# A tibble: 2 × 4
customer_id item_1 item_2 item_3
<dbl> <chr> <chr> <chr>
1 1 bread milk banana
2 2 milk toilet paper <NA> More tidying: reshaping
Basic Idea
- We have data that’s organized in way that doesn’t facilitate our analysis…..
- We want to reorganize the data so we can do the analysis
Time to figure out how!
Data: Sales
We have one row per customer, and in that row we have all the items the customer purchased in the columns.
We have…
Data: Sales
We have…
# A tibble: 2 × 4
customer_id item_1 item_2 item_3
<dbl> <chr> <chr> <chr>
1 1 bread milk banana
2 2 milk toilet paper <NA> We want…
# A tibble: 6 × 3
customer_id item_no item
<dbl> <chr> <chr>
1 1 item_1 bread
2 1 item_2 milk
3 1 item_3 banana
4 2 item_1 milk
5 2 item_2 toilet paper
6 2 item_3 <NA> A grammar of data tidying

The goal of tidyr is to help you tidy your data via
- pivoting for going between wide and long data
- splitting and combining character columns
- nesting and unnesting columns
- clarifying how
NAs should be treated
Data: Sales
We use “wider” and “longer” as relative terms
We have…
# A tibble: 2 × 4
customer_id item_1 item_2 item_3
<dbl> <chr> <chr> <chr>
1 1 bread milk banana
2 2 milk toilet paper <NA> We want…
# A tibble: 6 × 3
customer_id item_no item
<dbl> <chr> <chr>
1 1 item_1 bread
2 1 item_2 milk
3 1 item_3 banana
4 2 item_1 milk
5 2 item_2 toilet paper
6 2 item_3 <NA> We want to make this a longer data frame where each row represents one item purchased by one customer.
Pivoting data
Keep all of the data but change the shape of a data frame
How do we…?
Wider vs. longer
wider
more columns
# A tibble: 2 × 4
customer_id item_1 item_2 item_3
<dbl> <chr> <chr> <chr>
1 1 bread milk banana
2 2 milk toilet paper <NA> Wider vs. longer
wider
more columns
# A tibble: 2 × 4
customer_id item_1 item_2 item_3
<dbl> <chr> <chr> <chr>
1 1 bread milk banana
2 2 milk toilet paper <NA> longer
more rows
# A tibble: 6 × 3
customer_id item_no item
<dbl> <chr> <chr>
1 1 item_1 bread
2 1 item_2 milk
3 1 item_3 banana
4 2 item_1 milk
5 2 item_2 toilet paper
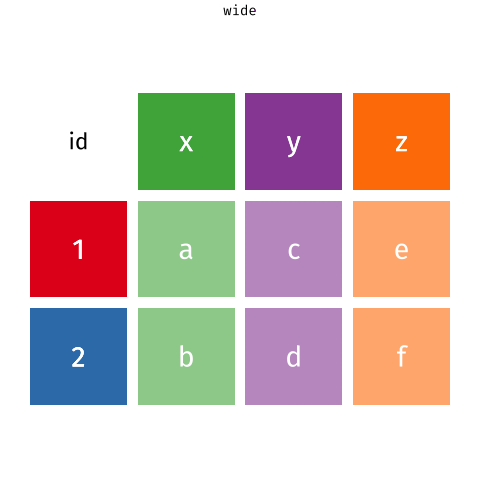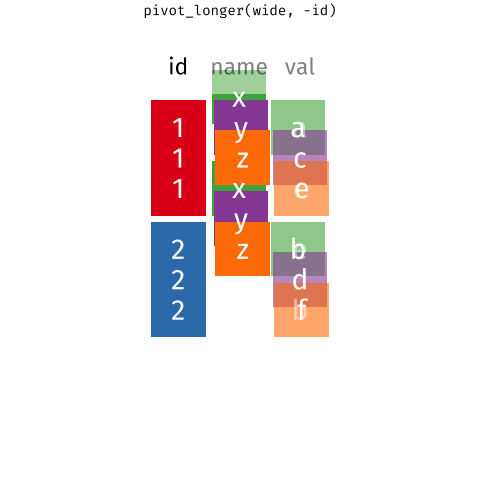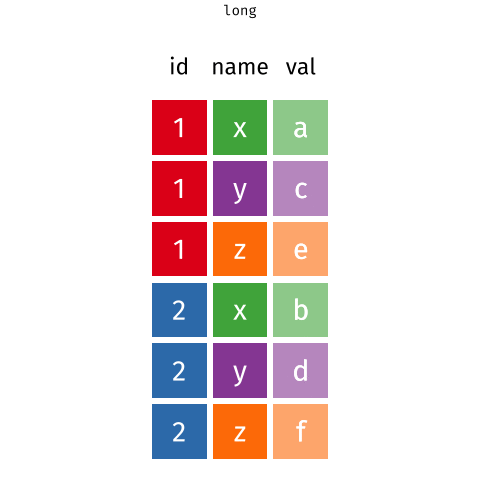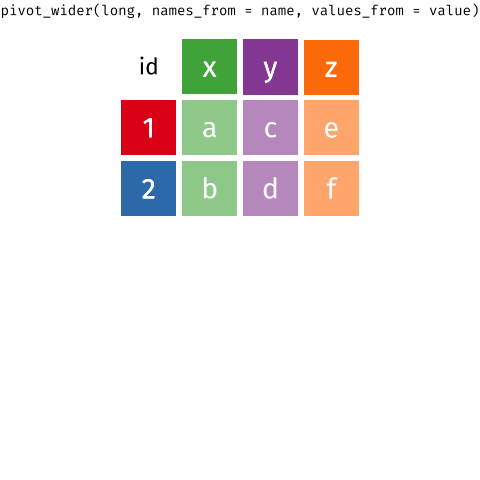
6 2 item_3 <NA> pivot_longer()
pivot_longer()
pivot_longer()
pivot_longer()
-
data(as usual) -
cols: columns to pivot into longer format -
names_to: name of the column where the column names of pivoted variables go (character string) -
values_to: name of the column where data in pivoted variables go (character string)
Customers \(\rightarrow\) purchases
purchases <- customers %>%
pivot_longer(
cols = item_1:item_3, # variables item_1 to item_3
names_to = "item_no", # column names -> new column called item_no
values_to = "item" # values in columns -> new column called item
)
purchases# A tibble: 6 × 3
customer_id item_no item
<dbl> <chr> <chr>
1 1 item_1 bread
2 1 item_2 milk
3 1 item_3 banana
4 2 item_1 milk
5 2 item_2 toilet paper
6 2 item_3 <NA> Why pivot?
Most likely, because the next step of your analysis needs it. More on left_join later…
Purchases \(\rightarrow\) customers
-
data(as usual) -
names_from: which column in the long format contains the what should be column names in the wide format -
values_from: which column in the long format contains the what should be values in the new columns in the wide format
Your turn…
Try the examples from the slides on your own.
More examples of pivoting
https://cran.r-project.org/web/packages/tidyr/vignettes/pivot.html